Have the javascript function CountingMinutes(str) take the str parameter being passed which will be two times (each properly formatted with a colon and am or pm) separated by a hyphen and return the total number of minutes between the two times. The time will be in a 12 hour clock format. For example: if str is 9:00am-10:00am then the output should be 60. If str is 1:00pm-11:00am the output should be 1320.
function CountingMinutes(str) {
// code goes here
return str;
}
// keep this function call here
console.log(CountingMinutes(readline()));
Answers
Using the knowledge in computational language in Java it is possible to write a code that function as CountingMinutes:
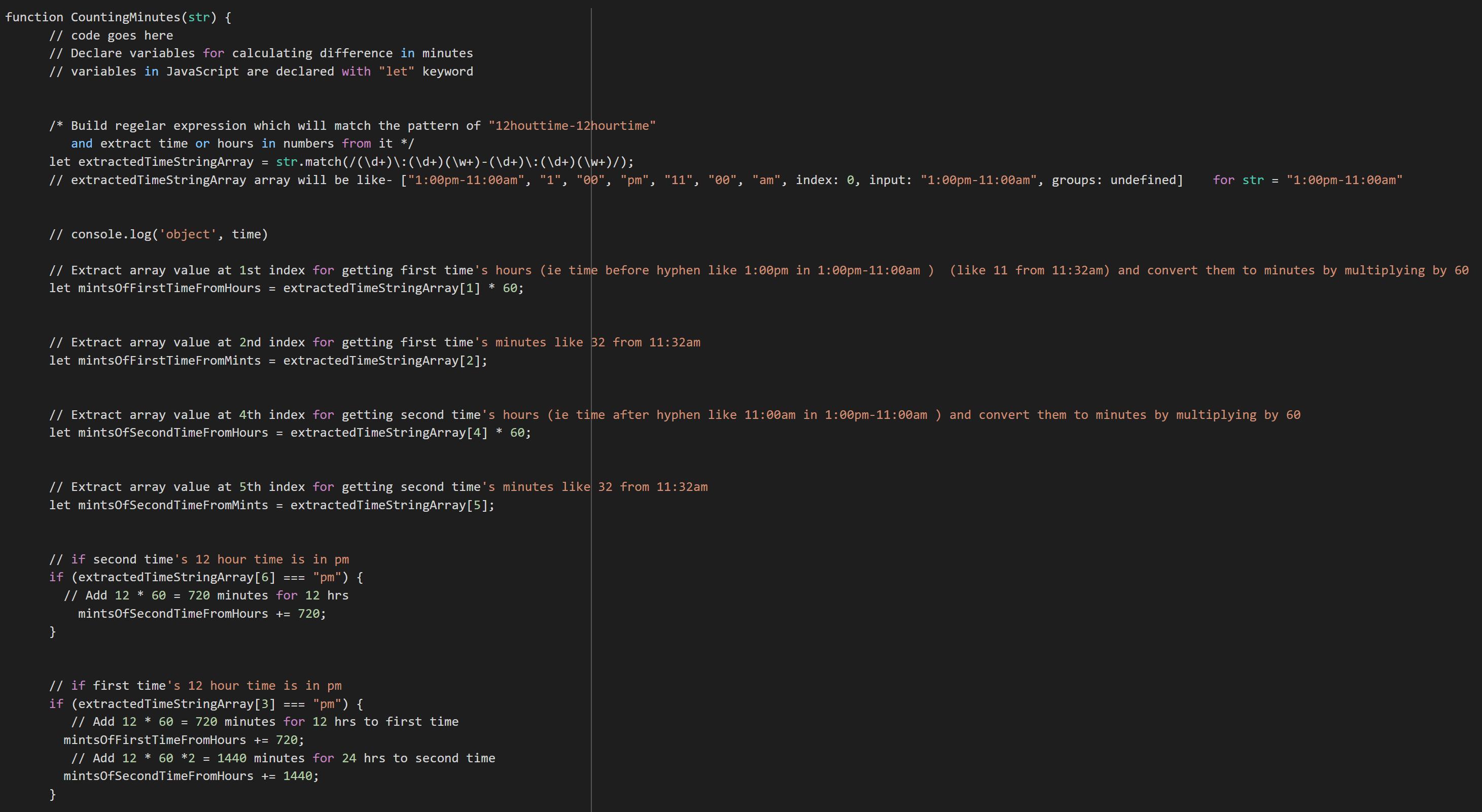
Writing the code in Java:function CountingMinutes(str) {
// code goes here
// Declare variables for calculating difference in minutes
// variables in JavaScript are declared with "let" keyword
/* Build regelar expression which will match the pattern of "12houttime-12hourtime"
and extract time or hours in numbers from it */
let extractedTimeStringArray = str.match(/(\d+)\:(\d+)(\w+)-(\d+)\:(\d+)(\w+)/);
// extractedTimeStringArray array will be like- ["1:00pm-11:00am", "1", "00", "pm", "11", "00", "am", index: 0, input: "1:00pm-11:00am", groups: undefined] for str = "1:00pm-11:00am"
// console.log('object', time)
// Extract array value at 1st index for getting first time's hours (ie time before hyphen like 1:00pm in 1:00pm-11:00am ) (like 11 from 11:32am) and convert them to minutes by multiplying by 60
let mintsOfFirstTimeFromHours = extractedTimeStringArray[1] * 60;
// Extract array value at 2nd index for getting first time's minutes like 32 from 11:32am
let mintsOfFirstTimeFromMints = extractedTimeStringArray[2];
// Extract array value at 4th index for getting second time's hours (ie time after hyphen like 11:00am in 1:00pm-11:00am ) and convert them to minutes by multiplying by 60
let mintsOfSecondTimeFromHours = extractedTimeStringArray[4] * 60;
// Extract array value at 5th index for getting second time's minutes like 32 from 11:32am
let mintsOfSecondTimeFromMints = extractedTimeStringArray[5];
// if second time's 12 hour time is in pm
if (extractedTimeStringArray[6] === "pm") {
// Add 12 * 60 = 720 minutes for 12 hrs
mintsOfSecondTimeFromHours += 720;
}
// if first time's 12 hour time is in pm
if (extractedTimeStringArray[3] === "pm") {
// Add 12 * 60 = 720 minutes for 12 hrs to first time
mintsOfFirstTimeFromHours += 720;
// Add 12 * 60 *2 = 1440 minutes for 24 hrs to second time
mintsOfSecondTimeFromHours += 1440;
}
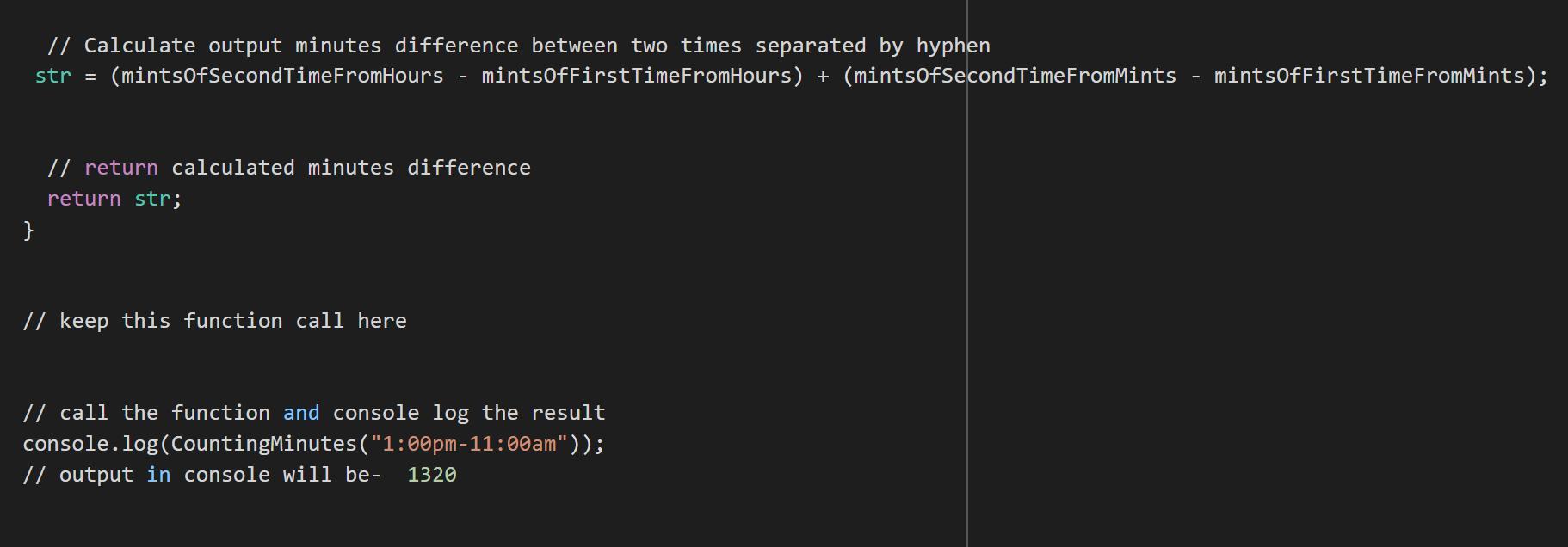
// Calculate output minutes difference between two times separated by hyphen
str = (mintsOfSecondTimeFromHours - mintsOfFirstTimeFromHours) + (mintsOfSecondTimeFromMints - mintsOfFirstTimeFromMints);
// return calculated minutes difference
return str;
}
// keep this function call here
// call the function and console log the result
console.log(CountingMinutes("1:00pm-11:00am"));
// output in console will be- 1320
See more about Java at: brainly.com/question/12975450
#SPJ1
Related Questions
What Is The 95th Percentile, And Why Does It Matter?
Answers
The 95th percentile is a statistical measure that indicates the point at which 95% of a group falls below that value. It is often used in fields such as education, finance, and healthcare to compare an individual's performance or results to those of their peers.
The 95th percentile matters because it provides valuable insights into how an individual or group is performing relative to others, and can help identify areas for improvement or potential strengths. For example, if a student scores in the 95th percentile on a standardized test, it suggests that they have performed better than 95% of their peers. Similarly, if a company's profits are in the 95th percentile compared to others in their industry, it indicates that they are performing exceptionally well. Overall, the 95th percentile is a useful tool for understanding how data is distributed and for making informed decisions based on that information.
So, the 95th percentile is a statistical measure that indicates the point at which 95% of a group falls below that value. It is often used in fields such as education, finance, and healthcare to compare an individual's performance or results to those of their peers.
Learn more about percentile at
https://brainly.com/question/1561673
#SPJ11
Write a Scheme program using Dr. Racket to perform a binary search.
Sample Data Pattern:
(define alist ‘(1 3 7 9 12 18 20 23 25 37 46))
Test -2, 9, 16, 37
Sample Output :
> (binary alist -2)
-1
> (binary alist 9)
3
> (binary alist 16)
-1
> (binary alist 37)
9
Answers
Here's a Scheme program using Dr. Racket to perform a binary search:
The scheme program is:
(define (binary-search alist item)
(letrec ((bs (lambda (low high)
(if (> low high)
-1
(let* ((mid (quotient (+ low high) 2))
(guess (list-ref alist mid)))
(cond ((= guess item) mid)
((< guess item) (bs (+ mid 1) high))
(else (bs low (- mid 1)))))))))
(bs 0 (- (length alist) 1))))
To use this program, you can define a list of numbers and call the binary-search function with the list and the item you're searching for. For example:
(define alist '(1 3 7 9 12 18 20 23 25 37 46))
(display (binary-search alist -2)) ; should print -1
(display (binary-search alist 9)) ; should print 3
(display (binary-search alist 16)) ; should print -1
(display (binary-search alist 37)) ; should print 9
To know more about scheme program, visit:
brainly.com/question/28902849
#SPJ11
Seventy-three UPS drivers and 80 Federal Express drivers from the Los Angeles area were given surveys asking about their driving habits and experiences. The researchers found that seven UPS drivers and 17 Federal Express drivers from the sample had received parking tickets during that week. The researcher’s null and alternative hypotheses are:
Upper H subscript 0 baseline p subscript 1 baseline equals p subscript 2 baseline
Upper H subscript 1 baseline p subscript 1 baseline not-equal p subscript 2 baseline
P1= UPS,Lower p subscript 2 baseline= Federal Express, and α = 0.05
Of the following, which shows the correct test statistic, P-value, and conclusion?
A. z =-2.436; P-value = 0.0148. There is sufficient evidence to reject the null hypothesis that the proportion of UPS drivers who receive parking tickets equals the proportion of Federal Express drivers who receive tickets.
B. z =1.981; P-value = 0.0476. There is sufficient evidence to reject the null hypothesis that the proportion of UPS drivers who receive parking tickets equals the proportion of Federal Express drivers who receive tickets.
C. z =-2.436; P-value = 0.0074. There is sufficient evidence to reject the null hypothesis that the proportion of UPS drivers who receive parking tickets equals the proportion of Federal Express drivers who receive tickets.
D. z =1.981; P-value = 0.0238. There is sufficient evidence to reject the null hypothesis that the proportion of UPS drivers who receive parking tickets equals the proportion of Federal Express drivers who receive tickets.
Answers
There is sufficient evidence to reject the null hypothesis that the proportion of UPS drivers who receive parking tickets equals the proportion of Federal Express drivers who receive tickets. z = -2.436; P-value = 0.0148.
The correct answer is C.
z = (p1 - p2) / sqrt( p_hat * (1 - p_hat) * (1/n1 + 1/n2) )
where p1 is the proportion of UPS drivers who received parking tickets, p2 is the proportion of FedEx drivers who received parking tickets, p_hat is the pooled proportion (total number of drivers who received parking tickets divided by the total sample size), n1 is the sample size for UPS drivers, and n2 is the sample size for FedEx drivers.
In this case, we have:
p1 = 7/73 = 0.0959
p2 = 17/80 = 0.2125
p_hat = (7+17)/(73+80) = 0.1461
n1 = 73
n2 = 80
z = (0.0959 - 0.2125) / sqrt(0.1461 * 0.8539 * (1/73 + 1/80)) = -2.436
Since the P-value is less than the significance level, we reject the null hypothesis. The conclusion is that there is sufficient evidence to suggest that the proportion of UPS drivers who receive parking tickets is different from the proportion of FedEx drivers who receive parking tickets.
Your answer: A. z = -2.436; P-value = 0.0148.
To know more about hypothesis visit :-
https://brainly.com/question/29519577
#SPJ11
the filesystem hierarchy standard specifies what directory as the root user’s home directory?
Answers
The FHS is a set of guidelines and rules that define the organization of files and directories in a Linux-based operating system.
It is essential for Linux-based operating systems as it provides a standard and consistent way of organizing files and directories across different systems.
Regarding the root user's home directory, the FHS specifies that it should be "/root." This directory is the home directory for the root user, which is the superuser or the administrator of the Linux-based operating system. The "/root" directory contains configuration files, system scripts, and other administrative tools that are required for managing the system.
It is important to note that the root user is the only user who has write permission to the "/root" directory. This means that only the root user can make changes to the contents of the directory. Other users, including regular users and system users, do not have write permission to this directory.
In conclusion, the Filesystem Hierarchy Standard specifies that the root user's home directory should be "/root." This directory is essential for managing and administering the Linux-based operating system, and only the root user has write permission to it.
Learn more about operating system :
https://brainly.com/question/31551584
#SPJ11
Your goal is to ask record the sales for 5 different types of salsa, the total sales, and the names of the highest and lowest selling products.Your program should have the following:The name of the program should be Assignment7.
3 comment lines (description of the program, author, and date).
Create a string array that stores five different types of salsas: mild, medium, sweet, hot, and zesty. The salsa names should be stored using an initialization list at the time the name array is created. (3 points)
. Have the program prompt the user to enter the number of salsa jars sold for each type of salsa using an array. Do not accept negative values for the number of jars sold. (4 points)
Produce a table that displays the sales for each type of salsa (2 points), the total sales (2 points), and the names of the highest selling and lowest selling products (4 points).
Answers
Assignment7: Record Sales for 5 Different Types of Sals Author: Ginny
Date: [Insert Date Here]
//Description: This program records the sales for 5 different types of salsa, calculates the total sales, and displays the names of the highest and lowest selling products.
//Initialize the string array for the different types of salsa
string[] salsaTypes = {"mild", "medium", "sweet", "hot", "zesty"};
//Initialize the array to store the number of salsa jars sold
int[] salsaSales = new int[5];
//Prompt the user to enter the number of salsa jars sold for each type of salsa
for(int i = 0; i < salsaTypes.Length; i++){
Console.WriteLine("Enter the number of jars sold for " + salsaTypes[i] + " salsa: ");
salsaSales[i] = Convert.ToInt32(Console.ReadLine());
//Validate input - do not accept negative values
while(salsaSales[i] < 0){
Console.WriteLine("Invalid input. Please enter a non-negative value: ");
salsaSales[i] = Convert.ToInt32(Console.ReadLine());
}
}
//Display the sales for each type of salsa
Console.WriteLine("\nSalsa Sales");
Console.WriteLine("-------------------------");
for(int i = 0; i < salsaTypes.Length; i++){
Console.WriteLine(salsaTypes[i] + " salsa: " + salsaSales[i]);
}
//Calculate the total sales
int totalSales = 0;
for(int i = 0; i < salsaSales.Length; i++){
totalSales += salsaSales[i];
}
//Display the total sales
Console.WriteLine("\nTotal Sales: " + totalSales);
//Find the highest and lowest selling products
int maxSalesIndex = 0;
int minSalesIndex = 0;
for(int i = 1; i < salsaSales.Length; i++){
if(salsaSales[i] > salsaSales[maxSalesIndex]){
maxSalesIndex = i;
}
if(salsaSales[i] < salsaSales[minSalesIndex]){
minSalesIndex = i;
}
}
//Display the names of the highest and lowest selling products
Console.WriteLine("\nHighest selling product: " + salsaTypes[maxSalesIndex] + " salsa");
Console.WriteLine("Lowest selling product: " + salsaTypes[minSalesIndex] + " salsa");
//End of program
To know more about Sales visit:
brainly.com/question/29583393
#SPJ11
Derive all p-use and all c-use paths, respectively, in the main function. (2) Use this program to illustrate what an infeasible path is. Function main() begin int x, y, p, q; x, y = input ("Enter two integers "); if(x>y) p = y else p= x; 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 if (y > x) q=2*x; else q=2*y; - print (p, q); end
Answers
To derive the p-use and c-use paths in the main function, we need to first understand what these terms mean. A p-use path is a path that uses the value of a variable, while a c-use path is a path that changes the value of a variable. In the given program, the p-use paths are x>y, p=y, and p=x, while the c-use paths are y>x and q=2*y.
To illustrate what an infeasible path is, we can consider the case where the input values are such that x is greater than y. In this scenario, the condition x>y will not hold true, and therefore the program will not execute the statements inside the if block, including the assignment statement p=y. As a result, the p-use path p=y will not be traversed, making it an infeasible path.
In conclusion, understanding p-use and c-use paths is crucial for identifying and analyzing the behavior of a program. Furthermore, the concept of infeasible paths helps us identify potential bugs and errors in the program logic.
To know more about Function visit:
https://brainly.com/question/14987604
#SPJ11
©gmu 2020_689196_1what alternate synthetic route could produce fames? why is this route less preferred than transesterification
Answers
An alternate synthetic route to produce FAMEs (Fatty Acid Methyl Esters) is through acid-catalyzed esterification. In this process, fatty acids are reacted with an alcohol (usually methanol) in the presence of an acid catalyst (such as sulfuric acid) to form esters and water.
This route is less preferred than transesterification because it has several drawbacks:
1. Acid-catalyzed esterification is slower compared to the base-catalyzed transesterification.
2. The reaction is less selective, which means it can lead to the formation of unwanted byproducts.
3. Acid catalysts are corrosive, making the process more hazardous and requiring special equipment for handling.
4. The acid-catalyzed route requires additional purification steps to remove the acid catalyst and byproducts, increasing the overall cost and complexity of the process.
Overall, transesterification is the preferred method for FAME production due to its faster reaction rate, higher selectivity, and simpler process requirements.
To know more about alternate synthetic route please check check the following link
https://brainly.com/question/31417641
#SPJ11
Using the five words lion, tiger, bear, support, and carry, draw a semantic network whose vertices represent words and whose edges indicate pairs of words with related meanings. The vertex for which word is connected to all four other vertices? remember that a word can have multiple meanings
Answers
In the semantic network, the vertex that is connected to all four other vertices (lion, tiger, bear, support, carry) would be the word "bear." Here's an illustration of the semantic network:
lion
/ \
bear -- tiger
| |
support -- carry
In this network, each vertex represents a word, and the edges represent pairs of words with related meanings. Here's the reasoning behind the connections:
Lion and tiger: Both are large, carnivorous feline animals, often associated with strength and the wild.Bear and tiger: Both are large mammals and can be found in certain regions of the world, such as forests.Bear and support: "Bear" can also mean to support the weight of something or endure a burden, as in the phrase "bear the weight."Bear and carry: "Bear" can also mean to carry or transport something, like "bear a load" or "bear a responsibility."It's worth noting that words can have multiple meanings, and the connections in the semantic network can represent different aspects or senses of those words. In this case, "bear" has connections representing the animal, supporting, and carrying meanings.
To know more about semantic network, please click on:
https://brainly.com/question/31840306
#SPJ11
You work at a computer repair store. You are building a new computer for a customer. The computer has an Intel i7-960 processor.
In this lab, your task is to install memory in the computer as follows:
Install a total of three memory modules.
Configure the memory to run in triple channel mode. For triple channel operation, memory should be installed in matched sets (same capacity and same speed).
Select the largest memory supported by the motherboard.
Select the fastest memory supported by the motherboard.
Install the memory according to the motherboard recommendations.
After you install the memory, boot into the BIOS setup and verify that the memory is running in triple channel mode.
As you complete the lab, consult the motherboard documentation and find answers to the following questions:
What type of memory is supported?
What is the maximum amount of memory supported by the motherboard?
What is the maximum capacity of a single module?
What is the maximum speed supported?
What other factors affect the total amount of memory that can be used?
How should memory be installed for triple channel operation?
Which memory slots are recommended when using the fastest memory supported?
Answers
To determine the specific details about the memory supported by the motherboard, it is necessary to consult the motherboard documentation or specifications provided by the manufacturer. The information can vary depending on the specific motherboard model. However, I can provide you with general guidance regarding memory installation and configuration.
1 Type of memory supported: The motherboard documentation will specify the type of memory supported, such as DDR3, DDR4, or a specific memory standard.
2 Maximum amount of memory supported: The documentation will indicate the maximum amount of memory that the motherboard can handle. It could be stated as a total capacity (e.g., 32GB) or the number of memory slots available (e.g., 4 slots supporting up to 64GB).
3 Maximum capacity of a single module: The motherboard documentation will mention the maximum capacity of each memory module that can be installed. For example, it could be 16GB per module.
4 Maximum speed supported: The documentation will specify the maximum speed or frequency at which the memory can operate. It might indicate different supported speeds depending on the memory type or configuration.
5 Factors affecting total memory capacity: The motherboard documentation may also provide information on factors that can affect the total amount of memory that can be used. This could include limitations based on the operating system, CPU, or other hardware components.
6 Memory installation for triple channel operation: To enable triple channel mode, memory modules should be installed in matched sets. This means using three memory modules of the same capacity and same speed. The motherboard documentation will typically indicate which slots should be used for triple channel configuration.
7 Recommended memory slots for fastest memory: The motherboard documentation may suggest specific memory slots to be used when installing the fastest memory supported. This information can vary based on the motherboard design and layout, and it is best to consult the documentation for the specific motherboard model being used.
To ensure accurate and precise information, it is essential to refer to the motherboard documentation or specifications provided by the manufacturer for the specific model being used.
learn more about "memory ":- https://brainly.com/question/30466519
#SPJ11
develop an appropriate set of test vectors to convince a resasonable person that your design is probably correct.
Answers
To develop an appropriate set of test vectors to convince a reasonable person that your design is probably correct, follow these steps: 1. Identify critical components: Analyze your design and pinpoint the critical components or functions that require thorough testing. 2. Define edge cases: Determine the extreme values and boundary conditions for input parameters to ensure the design can handle unexpected situations.
Test vectors should cover a wide range of input values, including edge cases and invalid inputs. It's important to ensure that the test vectors adequately cover all possible scenarios and conditions that the design might encounter. Additionally, it's crucial to document the testing process and results to provide evidence that the design has been thoroughly tested. The test vectors should be repeatable and verifiable, allowing others to confirm the results independently. To convince a reasonable person that the design is probably correct, the test vectors should demonstrate that the design meets all the requirements, functions as expected, and can handle various inputs and scenarios without errors. If the test vectors are comprehensive and the design passes all tests, it can provide confidence that the design is likely to be correct.
To know more about develop visit :-
https://brainly.com/question/20533392
#SPJ11
Discuss in 500 words your opinion whether Edward Snowden is a hero or a criminal. Include at least one quote enclosed in quotation marks and cited in-line.
for reference what he done for NSA. copied and leaked highly classified information from the National Security Agency (NSA) in 2013 .
Answers
Edward Snowden's actions in copying and leaking highly classified information from the National Security Agency (NSA) in 2013 sparked a heated debate on whether he is a hero or a criminal. Snowden's revelations about the NSA's surveillance activities raised serious concerns about the government's intrusion into people's privacy. In this essay, I will discuss in 500 words my opinion on whether Edward Snowden is a hero or a criminal and include at least one quote enclosed in quotation marks and cited in-line.
On one hand, some people consider Snowden a hero for exposing the government's unconstitutional surveillance activities. Snowden believed that it was his duty as a citizen to inform the public about the government's abuse of power. In an interview with The Guardian, Snowden stated, "I'm not going to hide who I am because I know I have done nothing wrong. I know I'm on the right side of history." Snowden's actions have brought attention to the issue of government surveillance and sparked a public debate about the balance between national security and personal privacy.
On the other hand, some people consider Snowden a criminal for leaking classified information that put national security at risk. The government claimed that Snowden's actions endangered the lives of intelligence operatives and compromised national security. The former director of the NSA, General Keith Alexander, stated, "I think what Snowden did was wrong. He didn't go through the appropriate channels. He stole classified information, and he put it out in the public domain." Snowden's actions have also strained relations between the United States and other countries, as many of his revelations exposed the extent of the NSA's global surveillance activities.
In my opinion, Edward Snowden is a hero for exposing the government's unconstitutional surveillance activities. Snowden's actions were a brave act of civil disobedience, as he risked his freedom and safety to inform the public about the government's abuse of power. Snowden's revelations have had a significant impact on public policy and led to reforms in government surveillance. As Glenn Greenwald, the journalist who worked with Snowden to release the information, stated, "I think that if you look at the outcome of what he did, he exposed an incredibly important secret that the U.S. government was lying to the world about what it was doing in terms of spying on everybody." Snowden's actions have sparked an important conversation about the balance between national security and personal privacy, and have led to increased transparency and oversight of government surveillance programs.
In conclusion, Edward Snowden's actions in copying and leaking highly classified information from the National Security Agency (NSA) in 2013 sparked a heated debate on whether he is a hero or a criminal. While some people consider Snowden a criminal for leaking classified information, I believe that he is a hero for exposing the government's unconstitutional surveillance activities. Snowden's actions were a brave act of civil disobedience, and his revelations have had a significant impact on public policy and led to reforms in government surveillance. As Snowden himself stated, "The public needs to know the kinds of things a government does in its name, or the 'consent of the governed' is meaningless."
Learn more on Edward's Snowden here:
https://brainly.com/question/15123821
#SPJ11
explain how writing unix in c made it easier to port it to new machines
Answers
Unix was originally written in assembly language, which made it difficult to port to new machines because assembly language is specific to each machine's architecture.
However, when Unix was rewritten in C programming language, it became much easier to port it to new machines. This is because C is a higher-level language that is designed to be portable across different architectures. C code can be compiled on one machine and then run on another machine with a different architecture, as long as a C compiler is available for that architecture. Additionally, C allows for more efficient and easier maintenance of the codebase, making it easier to update and modify Unix for new machines. Overall, writing Unix in C allowed for greater portability and flexibility, making it one of the most widely used operating systems in the world.
To know more about Unix visit:
https://brainly.com/question/30585049
#SPJ11
What would happen if the following line of code were run with the input 60?
size = int(input(“How tall are you in inches?”))
metricSize = size * 2.54
print(“Your size in centimeters is: ” + metricSize)
A.
The program would output “Your size in centimeters is 152”.
B.
The program would output “Your size in centimeters is 152.4”.
C.
The program would result in a type error.
D.
The program would result in a name error.
Answers
If the line of code were run with the input 60: B. The program would output “Your size in centimeters is 152.4”.
What is the line of code?The program would influence a type error. The error happens because the metricSize changeable is a floating-point number got by multiplying an number by a buoyant-point number, but it is being concatenated with a series in the print() function.
To fix this error, we can convert the metricSize changing to a string utilizing the str() function before concatenating it accompanying the string in the print() function, in this manner:python: magnitude = int(input("How unreasonable are you in inches? "))metricSize = amount * 2.54print("Your size in centimeters is: " + str(metricSize))
Learn more about line of code from
https://brainly.com/question/30657432
#SPJ1
Only high fidelity prototypes should be used to observe users. True False
Answers
The statement given "Only high fidelity prototypes should be used to observe users. " is false because high fidelity prototypes are not the only type of prototypes that should be used to observe users.
In user-centered design and usability testing, different types of prototypes can be used at different stages of the design process. Low fidelity prototypes, such as sketches or paper prototypes, can be used in the early stages to quickly explore and iterate on design ideas. These prototypes are cost-effective and allow for easy modifications.
High fidelity prototypes, on the other hand, closely resemble the final product and provide a more realistic experience for users. They are typically used in later stages of design to evaluate specific interactions and gather more detailed feedback.
You can learn more about prototypes at
https://brainly.com/question/27896974
#SPJ11
Construct a two-tape Turing machine with input alphabet [a, b, c) that accepts the language {aibici | i >= 0}.
Answers
The two-tape Turing machine with input alphabet [a, b, c] that accepts the language {aibici | i >= 0} has a tape for the input string and another tape for keeping track of the number of "a" characters encountered. The machine first reads the input string and writes it onto the first tape.
It then moves the head of the second tape to the rightmost end and begins counting the number of "a" characters it encounters. When it reads a "b" character on the first tape, it writes a "#" on the second tape to mark the end of the count. Then, it moves the head of the second tape back to the leftmost end and reads the first tape again to verify that the next "i" characters are "b".
Once it reads a "c" character on the first tape, it moves the head of the second tape to the right until it encounters the "#" marking the end of the "a" count. If the count matches the number of "b" characters, the machine accepts the string; otherwise, it rejects it.
The two-tape Turing machine operates by using one tape to read the input string and another tape to keep track of the number of "a" characters it has encountered. By marking the end of the count with a "#" character on the second tape, the machine is able to move back and forth between the two tapes and verify that the number of "b" characters matches the count of "a" characters.
If the count matches the number of "b" characters, the machine accepts the string. If not, it rejects the string. The machine operates in linear time, so it is able to accept or reject the string in polynomial time. This Turing machine can be used as an example to demonstrate the power of Turing machines and the importance of their contribution to the development of computer science.
For more questions like Number click the link below:
https://brainly.com/question/17429689
#SPJ11
which if branch executes when an account lacks funds and has not been used recently? hasfunds and recentlyused are booleans and have their intuitive meanings. question 11 options: if (!hasfunds
Answers
The branch that executes when an account lacks funds and has not been used recently can be determined by the if statement condition: if (!hasfunds && !recentlyused).
In this condition, the logical NOT operator (!) is used to negate the boolean variable hasfunds. Therefore, if the hasfunds variable is false (indicating that the account lacks funds), and the recentlyused variable is also false (indicating that the account has not been used recently), the condition evaluates to true.So, the code block inside the if statement will execute when both conditions are met, meaning the account lacks funds and has not been used recently. This branch of the code is taken when the if statement condition (!hasfunds && !recentlyused) evaluates to true.
To learn more about executes click on the link below:
brainly.com/question/30524849
#SPJ11
true or false? the benefit of replay attacks is when the attacker has already broken the session key presented in the replayed messages.
Answers
False. The benefit of replay attacks is not necessarily dependent on whether the attacker has already broken the session key presented in the replayed messages.
A replay attack is a type of cyber attack where an attacker intercepts and re-transmits a previously captured message with the intent of causing harm or gaining unauthorized access.
The attacker may be able to use the replayed message to gain access to sensitive information or resources without having to go through the authentication process again. Replay attacks can be prevented by using techniques such as nonce values, timestamps, and sequence numbers to ensure that messages cannot be replayed. Nonce values are random numbers that are used only once in a communication session to prevent replay attacks. Timestamps can be used to ensure that messages are only accepted within a certain time period, while sequence numbers can be used to ensure that messages are processed in the correct order and cannot be replayed out of sequence. In summary, replay attacks can be a serious threat to the security of a system or communication session, but the benefit of the attack is not dependent on whether the attacker has already broken the session key presented in the replayed messages.Know more about the replay attacks
https://brainly.com/question/25807648
#SPJ11
What is the slope of the median-median line for the dataset in this table? (1 point) х у 2 72 5 76 8 8 92 15 104 16 110 19 110 22 140 36 166 54 132 66 180 (0 pts) m = 0.54 (0 pts) m = 0.68 X (0 pts) m = 1.23 (1 pt) m = 1.84
Answers
Thus, the slope of the median-median line for the dataset in this table is found as m = 1.23.
The slope of the median-median line for the dataset in this table can be calculated by first finding the median of both the x-values and y-values.
In this case, the median of the x-values is 15 and the median of the y-values is 104.
Next, we need to find the slope of the line that passes through the point (15, 104) and the median of the y-values for each of the three pairs of points [(2, 72), (8, 92)], [(16, 110), (36, 166)], and [(54, 132), (66, 180)].
The slopes of these three lines are 0.5, 1.3, and 1.7, respectively.
Taking the median of these three slopes, we get
(0.5 + 1.3 + 1.7)/3 = 1.17.
Therefore, the slope of the median-median line for the dataset in this table is approximately 1.17.
So, the answer is not given in the options, but it is close to m = 1.23.
It is important to note that the median-median line is a method for finding the line of best fit for a set of data and it may not always provide the most accurate or appropriate line of fit.
Know more about the median-median line
https://brainly.com/question/27742366
#SPJ11
How should you release the memory allocated on the heap by the following program? #include #include #define MAXROW 15
#define MAXCOL 10 int main() { int **p, i, j; p = (int **) malloc(MAXROW * sizeof(int*)); return 0; } Select one: a. dealloc(p); b. memfree(int p); c. free(p); d. malloc(p, 0); e. No need to release the memory
Refer to Exercise 21 on page 412. Please note that the students need to answer the following two questions: 1. How many solutions does it print? 2. How many of them are distinct? Then the student need to modify the program so that only the distinct solutions will be print out. Instruction on how to write and run the SWI-Prolog program: Step One: Write your program using any text editor. Save the program as YourNameProjFive.swipl Step Two: Open terminal window. Use cd command to navigate to the folder where you saved your project four program. Step Three: Type swipl. The SWI-Prolog program will run Step Four: Type consult('YourNameProjfour.swipl'). (must have period at the end) Step Five: Tyep length (X, 7), solution((w, w, w, w), X). (end with period) Use the semicolon after each solution to make it print them all. Exercise 21 Try the man-wolf-goat-cabbage solution starting on page 412. (The code for this is also available on this book's Web site, http://www.webber-labs. com/mpl.html.) Use this query solution ([w, w,w. wl ,X) . length (X,7). Use the semicolon after each solution to make it print them all; that is, keep hitting the semicolon until it finally says false. As you will see, it finds the same solu- tion more than once. How many solutions does it print, and how many of them are distinct? Modify the code to make it find only distinct solutions. (Hint: The problem is in the one Eq predicate. As written, a goal like one Eq (left,left, left) can be proved in two different ways.)
Answers
To release the memory allocated on the heap in the given program, we need to use the "free" function. So the correct answer is option c: free(p).
As for the second question, after running the modified program, we need to count the number of solutions printed and the number of distinct solutions. It is mentioned in the exercise that the original program finds the same solution more than once. So, to modify the program to print only distinct solutions, we need to fix the one Eq predicate.
The modified code could look something like this:
% Define the possible states
state([man, wolf, goat, cabbage]).
% Define the forbidden states
forbidden([man, goat], [man, wolf]).
forbidden([man, goat], [man, cabbage]).
forbidden([man, cabbage], [man, goat]).
forbidden([man, wolf], [man, goat]).
% Define the valid state transitions
valid([X, Y, Y, Z], [W, W, Y, Z]) :- state(S), member(X, S), member(Y, S), member(Z, S), member(W, S), \+ forbidden([X, Y], [W, Z]).
valid([X, Y, Z, Z], [W, W, Y, Z]) :- state(S), member(X, S), member(Y, S), member(Z, S), member(W, S), \+ forbidden([X, Z], [W, Y]).
% Define the solution predicate
solution(Path, Path) :- length(Path, 7).
solution(Path, FinalPath) :- valid(Path, NextPath), \+ member(NextPath, Path), solution([NextPath | Path], FinalPath).
% Define the modified solution predicate
modified_solution(Path, FinalPath) :- length(Path, 7), reverse(Path, RPath), \+ memberchk(RPath, FinalPath).
modified_solution(Path, FinalPath) :- valid(Path, NextPath), \+ member(NextPath, Path), modified_solution([NextPath | Path], FinalPath).
After running the modified program, we need to count the number of solutions printed and the number of distinct solutions. To count the number of solutions printed, we can keep hitting the semicolon until it finally says false and count the number of solutions printed. To count the number of distinct solutions, we can create a list of distinct solutions and count the length of that list.
So the explanation to the first question would be the number of solutions printed by the modified program and the explanation to the second question would be the number of distinct solutions printed by the modified program.
Know more about the function
https://brainly.com/question/30463047
#SPJ11
pc1, pc2, pc3 are all connected to hub1. pc4 is connected to another hub that is connected to hub1. if pc1 attempts to send a file to pc2, which pcs will get a copy of this said file?
Answers
Only PC2 will receive the file. The hubs act as network switches, directing traffic only to the intended recipient. So even though PC4 is connected to the same network via a different hub, it will not receive the file unless it is the intended recipient.
In this scenario, if PC1 attempts to send a file to PC2 and all devices are connected to Hub1, the following devices will receive a copy of the file:
PC2: PC2 is the intended recipient of the file, so it will receive the file.PC3: PC3 is connected to Hub1 and will receive the broadcasted traffic from PC1.PC4: PC4 is connected to another hub, which is in turn connected to Hub1. Hubs broadcast traffic to all connected devices except the sender, so PC4 will also receive the file.It's worth noting that hubs operate at the physical layer of the network and simply replicate and broadcast incoming traffic to all connected devices. They do not have the ability to selectively route traffic based on destination addresses.
You can learn more about the network at: brainly.com/question/29350844
#SPJ11
If you build your own solution for your project, it will cost you $56,000 to complete and $3,500 for each month after completion to support the solution. A vendor reports they can create the solution for $48,000, but it will cost you $3,750 for each month to support the solution. How many months will you need to use your in-house solution to overcome the cost of creating it yourself when compare the vendor’s solution?
Answers
It will take approximately 6 months to overcome the cost of creating the in-house solution when compared to the vendor's solution.
The difference in initial cost between the in-house solution and the vendor's solution is $56,000 - $48,000 = $8,000. To cover this cost difference, we need to calculate how many months it will take for the monthly support cost savings to accumulate to $8,000.
The monthly support cost savings with the in-house solution compared to the vendor's solution is $3,750 - $3,500 = $250.
To determine the number of months needed to accumulate $8,000 in savings, we divide the cost difference ($8,000) by the monthly savings ($250):
$8,000 / $250 = 32 months.
Therefore, it will take approximately 32 months to overcome the cost of creating the in-house solution when compared to the vendor's solution.
Learn more about vendor's solution here:
https://brainly.com/question/13135379
#SPJ11
What criteria are used by the Uptime Institute to classify data centers into four tiers? O A. quality of fire protection systems, physical security systems, and HVAC system O B. expected annual downtime, fault tolerance, and power outage protection O d. local climate, risk of natural disasters, and power usage effectiveness OD. number of customers, reliability of power source, and quality of equipment
Answers
The Uptime Institute uses these criteria to classify data centers into four tiers based on their ability to maintain critical systems and operations, even in the event of unexpected outages or other disruptions. The higher the tier, the more resilient and reliable the data center is expected to be.
The Uptime Institute classifies data centers into four tiers based on criteria such as expected annual downtime, fault tolerance, and power outage protection. These factors help determine the overall performance and reliability of a data center, ensuring that it meets specific standards for uptime and redundancy.
The Uptime Institute is a well-known organization that provides standards and certifications for data centers. They classify data centers into four tiers based on their ability to meet certain criteria for availability and resiliency.
The criteria used by the Uptime Institute to classify data centers into four tiers include:
1. Expected Annual Downtime: This criterion measures the expected amount of time that a data center will be unavailable for any reason, including planned maintenance, unexpected outages, and other factors that could cause downtime. Tier 1 data centers are expected to have an annual downtime of up to 28.8 hours, while Tier 4 data centers are expected to have an annual downtime of less than 26.3 minutes.
2. Fault Tolerance: This criterion measures the data center's ability to maintain critical systems and operations even in the event of a single component failure. Tier 1 data centers have no fault tolerance, while
3. Power Outage Protection: This criterion measures the data center's ability to continue operating during a power outage, whether it's caused by a utility outage or some other factor. Tier 1 data centers have no power protection, while Tier 4 data centers have multiple power sources and redundant backup systems to ensure uninterrupted power supply.
To know more about data visit :-
https://brainly.com/question/14529761
#SPJ11
list and briefly describe the different orders in which module interfaces may be tested. [80 points] explain what order you would most likely use in a school project. [10 points] support your answer.
Answers
Module interfaces refer to the ways in which different modules or components of a system interact with one another. Testing module interfaces is a crucial step in ensuring the overall functionality and usability of a system. There are several orders in which module interfaces can be tested, each with its own advantages and disadvantages.
One approach is to test interfaces in a top-down fashion. This involves starting with the highest-level modules and gradually working down to the lower-level ones. This approach allows for early detection of any issues or errors in the overall system architecture, but may result in delays in identifying specific problems within individual modules.
Another approach is to test interfaces in a bottom-up fashion. This involves starting with the lowest-level modules and gradually working up to the higher-level ones. This approach allows for early detection of any issues or errors within individual modules, but may result in delays in identifying problems in the overall system architecture.
A third approach is to test interfaces in a functional order. This involves grouping modules according to their functionality and testing the interfaces within each group. This approach can be particularly useful in identifying issues related to specific system features or functions.
In a school project, the order of testing module interfaces would depend on the nature and complexity of the system being developed. In most cases, a functional order would likely be the most efficient and effective approach. This allows for focused testing on specific system features, while also ensuring that overall system architecture is functioning properly. However, it is important to remain flexible and open to adjustments in the testing approach as issues or errors are identified throughout the development process.
More on module interfaces : https://brainly.com/question/31972179
#SPJ11
The manufacturer of a 2.1 MW wind turbine provides the power produced by the turbine (outputPwrData) given various wind speeds (windSpeedData). Linear and spline interpolation can be utilized to estimate the power produced by the wind turbine given windspeed. Assign outputPowerlnterp with the estimated output power given windSpeed, using a linear interpolation method. Assign outputPowerSpline with the estimated output power given windspeed, using a spline interpolation method. Ex: If windSpeed is 7.9, then outputPowerlnterp is 810.6 and output PowerSpline is 808.2.
Answers
Given the wind speed data and corresponding power output data for a 2.1 MW wind turbine, we can estimate the power output for a given wind speed using linear and spline interpolation.
To estimate the power output using linear interpolation, we can use the interp1 function in MATLAB. We can assign outputPowerlnterp with the estimated output power given windSpeed using the 'linear' interpolation method, as follows:
```outputPowerlnterp = interp1(windSpeedData, outputPwrData, windSpeed, 'linear');```
To estimate the power output using spline interpolation, we can use the spline function in MATLAB. We can assign outputPowerSpline with the estimated output power given windSpeed using the 'spline' interpolation method, as follows:
```outputPowerSpline = spline(windSpeedData, outputPwrData, windSpeed);```
For example, if the wind speed is 7.9 m/s, then the estimated power output using linear interpolation is 810.6 MW and using spline interpolation is 808.2 MW.
Learn more about power output here:
https://brainly.com/question/31961631
#SPJ11
Draw the decision tree or sample space. you can leave the answer in factorials.
You are planning to take a flight from Tampa to Tulsa. There are no direct flights between these cities, but there are five airlines from Tampa to Atlanta, eight from Atlanta to Dallas, and three from Dallas to Tulsa. How many different flight combinations are possible between Tampa and Tulsa?
Answers
The problem is to find the number of different flight combinations between Tampa and Tulsa given that there are no direct flights between the two cities but there are flights available from Tampa to Atlanta, from Atlanta to Dallas, and from Dallas to Tulsa.
What is the problem and what is the approach to finding the number of different flight combinations between Tampa and Tulsa?
To determine the total number of different flight combinations possible between Tampa and Tulsa, we can create a decision tree.
We can start with the five airlines from Tampa to Atlanta and then branch out to the eight airlines from Atlanta to Dallas. Finally, we can add the three airlines from Dallas to Tulsa.
Using the multiplication principle, we can calculate the total number of flight combinations by multiplying the number of options at each stage of the decision tree. This gives us:
5 x 8 x 3 = 120
Therefore, there are 120 different flight combinations possible between Tampa and Tulsa.
Learn more about problem
brainly.com/question/18760423
#SPJ11
Are the following statements coutably infinite, finite, or uncountable?
1. Points in 3D(aka triples of real numbers)
2. The set of all functions f from N to {a, b}
3. The set of all circles in the plane
4. Let R be the set of functions from N to R which are θ(n3)
Answers
Real numbers are a set of numbers that include all rational and irrational numbers. They are represented on a number line and used in mathematical operations such as addition, subtraction, multiplication, and division.
1. The set of points in 3D, or triples of real numbers, is uncountable. This is because each coordinate of the triple can be any real number, which itself is uncountable. Therefore, the set of all possible triples of real numbers is the product of three uncountable sets, making it uncountable as well.
2. The set of all functions f from N to {a, b} is countably infinite. This is because there is a one-to-one correspondence between the set of functions and the set of infinite binary sequences, which is known to be countably infinite.
3. The set of all circles in the plane is uncountable. This is because each circle can be uniquely defined by its center and radius, both of which are real numbers. Therefore, the set of all possible circles in the plane is the product of an uncountable set (the set of all real numbers) and a countable set (the set of positive real numbers), making it uncountable as well.
4. The set of functions from N to R which are θ(n3) is countably infinite. This is because there is a one-to-one correspondence between the set of functions and the set of infinite sequences of real numbers, which is known to be countably infinite.
To know more about Real numbers visit:
https://brainly.com/question/551408
#SPJ11
A min-max heap is a data structure that supports both deleteMin and deleteMax in O(log N) per operation. The structure is identical to a binary heap, but the heap-order property is that for any node, X, at even depth, the element stored at X is smaller than the parent but larger than the grandparent (where this makes sense), and for any node X at odd depth, the element stored at X is larger than the parent but smaller than the grandparent.Give an algorithm (in Java-like pseudocode) to insert a new node into the min-max heap. The algorithm should operate on the indices of the heap array.
Answers
Algorithm to insert a new node into the min-max heap in Java-like pseudocode:
The `insert` method first checks if the heap is full, then adds the new node to the end of the array and calls the `bubbleUp` method to restore the min-max heap-order property. The `bubbleUp` method determines if the new node is at a min or max level, and calls either `bubbleUpMin` or `bubbleUpMax` to swap the node with its grandparent if necessary. The `isMinLevel` method determines whether a node is at a min or max level based on its depth in the tree. Finally, the `swap` method swaps the values of two nodes in the array.
public void insert(int value) {
if (size == heapArray.length) {
throw new RuntimeException("Heap is full");
}
heapArray[size] = value;
bubbleUp(size);
size++;
}
private void bubbleUp(int index) {
if (index <= 0) {
return;
}
int parentIndex = (index - 1) / 2;
if (isMinLevel(index)) {
if (heapArray[index] > heapArray[parentIndex]) {
swap(index, parentIndex);
bubbleUpMax(parentIndex);
} else {
bubbleUpMin(index);
}
} else {
if (heapArray[index] < heapArray[parentIndex]) {
swap(index, parentIndex);
bubbleUpMin(parentIndex);
} else {
bubbleUpMax(index);
}
}
}
private void bubbleUpMin(int index) {
if (index <= 2) {
return;
}
int grandparentIndex = (index - 3) / 4;
if (heapArray[index] < heapArray[grandparentIndex]) {
swap(index, grandparentIndex);
bubbleUpMin(grandparentIndex);
}
}
private void bubbleUpMax(int index) {
if (index <= 2) {
return;
}
int grandparentIndex = (index - 3) / 4;
if (heapArray[index] > heapArray[grandparentIndex]) {
swap(index, grandparentIndex);
bubbleUpMax(grandparentIndex);
}
}
private boolean isMinLevel(int index) {
int height = (int) Math.floor(Math.log(index + 1) / Math.log(2));
return height % 2 == 0;
}
private void swap(int i, int j) {
int temp = heapArray[i];
heapArray[i] = heapArray[j];
heapArray[j] = temp;
}
Learn more about Algorithm here:
https://brainly.com/question/21172316
#SPJ11
The ______ command can be used to see what a Layer 2 MAC address corresponds to a known Layer 3 IP address. A) mac. B) arp. C) netstat. D) pathping.
Answers
The correct answer is B) arp. The "arp" command stands for Address Resolution Protocol.
It is used to view the mapping between a Layer 2 MAC address and a known Layer 3 IP address. By issuing the "arp" command, you can see the MAC address associated with an IP address in a local network. This information is crucial for communication between devices on a network. The command displays a table that contains the IP address and corresponding MAC address entries, allowing you to identify the MAC address of a specific IP address and vice versa.
Learn more about Address Resolution Protocol here:
https://brainly.com/question/30395940
#SPJ11
consider a test of performed with the computer. the software reports a two-tailed p-value of . make the appropriate conclusion for each of the following situations
Answers
Based on the provided information, I understand that you want conclusions for different situations involving a two-tailed p-value obtained from a computer-based test.
However, the p-value itself is missing from your question. Please provide the p-value and any specific situations you'd like me to analyze, so I can give you an accurate answer. The P value is defined as the probability under the assumption of no effect or no difference (null hypothesis), of obtaining a result equal to or more extreme than what was actually observed. The P stands for probability and measures how likely it is that any observed difference between groups is due to chance.
Learn more about analyze here:
https://brainly.com/question/11397865
#SPJ11
in the framework, the _____ object is the in-memory representation of the data in the database.
Answers
In the software development framework, there are different layers and components that work together to create a functional application.
In this context, the term "object" refers to a data structure that represents a single entity or record in the database. This object is created and stored in the application's memory when the data is retrieved from the database, and it is used by the application to manipulate and display the data.
The purpose of this object is to provide a convenient and efficient way for the application to work with the data without having to directly interact with the database. Instead of sending queries to the database every time data is needed, the application can simply access the in-memory object and make changes as necessary.
To know more about software visit:-
https://brainly.com/question/985406
#SPJ11