Answers
Step-by-step explanation:
we have
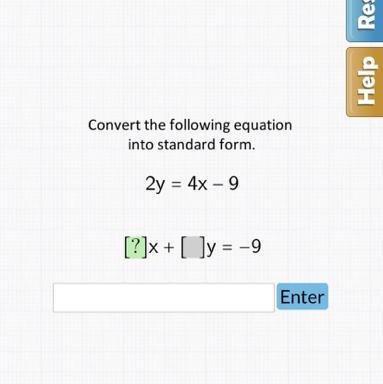
2y = 4x - 9
and we want it to look like
...x + ...y = -9
simple.
the y term is already on the left side. we need to move the x term to the same side.
what do we do ? we subtract the term we want to get rid of on one side from both sides (we always have to do changes in both sides of the equation, or we change the whole meaning of the equation).
2y = 4x - 9 | -4x on both sides
-4x + 2y = -9
and we are finished. that's it.
Answer:
-4x + 2y = -9
Step-by-step explanation:
Pre-Solving InformationWe are given the equation 2y=4x-9, and we want to convert it into standard form.
Standard form is written as ax+by=c, where a, b, and c are free integer coefficients, however a and b cannot be 0.
SolvingNotice how in standard form, x and y are on the same side. Currently, x and y are on different sides.
Therefore, we first need to get x and y on the same side.
We can do this by subtracting 4x from both sides.
2y = 4x - 9
-4x -4x
_____________
-4x + 2y = -9
As indicated by the -9 on the left side, we have solved the question, and are now done.
Hence, the answer is -4x + 2y = -9.
Related Questions
according to cohen's guidelines for the pearson correlation coefficient (r), a correlation of r = 0.50 would be a _______ correlation.
Answers
According to Cohen's guidelines, a Pearson correlation coefficient (r) of 0.50 would be considered a moderate correlation. Cohen's guidelines suggest that correlations between 0.30 and 0.49 are considered small, correlations between 0.50 and 0.69 are moderate, and correlations of 0.70 and above are large.
A correlation coefficient of 0.50 indicates a positive relationship between two variables, meaning that as one variable increases, the other variable tends to increase as well. The strength of the correlation indicates the degree to which the two variables are related: a moderate correlation indicates a fairly strong relationship, but not as strong as a large correlation (which would indicate a very strong relationship).
It is important to note that correlation does not imply causation, and that other factors may be at play in determining the relationship between two variables. Additionally, correlation coefficients can be influenced by outliers, non-linear relationships, or other factors that may not be immediately apparent.
In conclusion, a Pearson correlation coefficient of 0.50 would be considered a moderate correlation according to Cohen's guidelines. While a moderate correlation indicates a fairly strong relationship between two variables, it is important to carefully consider other factors that may be influencing the relationship, and to avoid making causal inferences based on correlation alone.
To know more about Cohen's guidelines visit:
https://brainly.com/question/31538595
#SPJ11
assume a is 100x10^6 which problem would you solve, the primal or the dual
Answers
Assuming that "a" refers to a matrix with dimensions of 100x10^6, it is highly unlikely that either the primal or dual problem would be solvable using traditional methods.
if "a" is assumed a much smaller matrix with dimensions that were suitable for traditional methods, then the answer would depend on the specific problem being solved and the preference of the solver.
In general, the primal problem is used to maximize a linear objective function subject to linear constraints, while the dual problem is used to minimize a linear objective function subject to linear constraints.
So, if the problem involves maximizing a linear objective function, then the primal problem would likely be solved.
If the problem involves minimizing a linear objective function, then the dual problem would likely be solved.
Read more about the Matrix.
https://brainly.com/question/31017647
#SPJ11
a traveler can choose from three airlines, five hotels, and four rental car companies. how many arrangements of these services are possible?
Answers
60 possible arrangements when a traveler can choose from three airlines, five hotels, and four rental car companies.
Number of airlines = 3
Number of hotels = 5
Number of rental car companies = 4
To calculate the total number of arrangements, we will multiply these numbers together
Total number of arrangements = Number of airlines × Number of hotels × Number of rental car companies
Total number of arrangements = 3 × 5 × 4
Total number of arrangements = 60
Therefore, there are 60 possible arrangements when a traveler can choose from three airlines, five hotels, and four rental car companies.
To know more about arrangements click here :
https://brainly.com/question/30435320
#SPJ4
statistical process control tools are used most frequently because
Answers
Statistical process control (SPC) tools are used most frequently because they provide a systematic and data-driven approach to monitor and improve processes.
The main advantage of using SPC tools is that they enable organizations to detect and respond to variations in their processes. By collecting and analyzing data over time, SPC tools help identify patterns, trends, and abnormalities in the process performance.
This allows for timely intervention and corrective actions to be taken, reducing the likelihood of defects, errors, and inefficiencies. SPC tools provide a proactive approach to quality management, helping organizations maintain consistency and meet customer requirements.
Furthermore, SPC tools provide objective and quantitative measures of process performance. They use statistical techniques to measure process capability, control limits, and performance indicators such as mean, standard deviation, and control charts.
This allows organizations to make data-driven decisions and prioritize improvement efforts based on reliable information rather than subjective assessments.
SPC tools also provide a common language and framework for quality improvement efforts, facilitating communication and collaboration among team members.
To know more about data click here
brainly.com/question/11941925
#SPJ11
The work shows finding the sum of the algebraic expressions –3a 2b and 5a (–7b). –3a 2b 5a (–7b) Step 1: –3a 5a 2b (–7b) Step 2: (–3 5)a [2 (–7)]b Step 3: 2a (–5b) Which is used in each step to simplify the sum? Step 1: Step 2: Step 3:.
Answers
The expression given is –3a 2b + 5a (–7b). We need to find the sum of this algebraic expression. Step 1:We need to simplify the given expression. To simplify, we will use the distributive property.
-3a 2b + 5a (–7b) = -3a 2b – 35abStep 2:Now, we need to simplify further. For this, we will take out the common factors.-3a 2b – 35ab = –a(3b + 35)Step 3:So, the final expression is –a(3b + 35). Therefore, the steps used to simplify the given expression are as follows:Step 1: Simplify the given expression using distributive property.-3a 2b + 5a (–7b) = -3a 2b – 35abStep 2: Take out the common factor -a.-3a 2b – 35ab = –a(3b + 35)Step 3: The final expression is –a(3b + 35).Hence, we have found the sum of the given algebraic expression and also the steps used to simplify the expression.
To know more about sum visit:
brainly.com/question/31538098
#SPJ11
if the surface area of a cube is 864cm2, what is the volume of the cube PLEASE ANSWER QUICKLY
Answers
The volume of the cube is 1728 cm³.
How to find the volume of the cube?The surface area of a cube is given by the formula:
A = 6S²
where S is the side length of the cube.
In this case, the surface area is 864 cm². Thus, we have:
864 = 6S²
Dividing both sides of the equation by 6, we get:
S² = 864/6
S² = 144
Taking the square root of both sides:
S = √144
S = 12 cm
The volume of a cube is given by:
V = S³
V = 12³
V = 1728 cm³
Learn more about volume of cube on:
https://brainly.com/question/29137123
#SPJ1
Determine the value of c such that the function f(x,y)=cxy for0
a) P(X<2,Y<3)
b) P(X<2.5)
c) P(1
d) P(X>1.8, 1
e) E(X)
Answers
To determine the value of c such that the function f(x,y) = cxy is a joint probability density function, we need to use the fact that the total probability over the entire sample space is equal to 1. That is:
∬R f(x,y) dxdy = 1
where R is the region over which f(x,y) is defined.
a) P(X<2,Y<3) can be calculated as:
∫0^2 ∫0^3 cxy dy dx = c/2 * [y^2]0^3 * [x]0^2 = 27c/2
b) P(X<2.5) can be calculated as:
∫0^2.5 ∫0^∞ cxy dy dx = ∞ (as the integral diverges unless c=0)
c) P(1<d<2) can be calculated as:
∫1^2 ∫0^∞ cxy dy dx = c/2 * [y^2]0^∞ * [x]1^2 = ∞ (as the integral diverges unless c=0)
d) P(X>1.8, 1<Y<3) can be calculated as:
∫1.8^2 ∫1^3 cxy dy dx = c/2 * [(3^2-1^2)-(1.8^2-1^2)] * (2-1) = 0.49c
e) To calculate E(X), we first need to find the marginal distribution of X, which can be obtained by integrating f(x,y) over y:
fx(x) = ∫0^∞ f(x,y) dy = cx/2 * ∫0^∞ y^2 dy = ∞ (as the integral diverges unless c=0)
Therefore, E(X) does not exist unless c=0.
In conclusion, we can see that unless c=0, the joint probability density function f(x,y)=cxy does not meet the criteria of being a valid probability distribution.
To know more about probability distribution, visit:
https://brainly.com/question/14210034
#SPJ11
determine whether the statement below is true or false. if it is false, rewrite it as a true statement. the number of different ordered arrangements of n distinct objects is n!.
Answers
True, the number of different ordered arrangements of n distinct objects is indeed n!.
Is the statement "The number of different ordered arrangements of n distinct objects is n!" true or false?In permutations, the order of arrangement is crucial.
When considering n distinct objects, there are n choices for the first position, (n-1) choices for the second position (as one object has already been placed), (n-2) choices for the third position, and so on.
To calculate the total number of permutations, we multiply all the choices together: n * (n-1) * (n-2) * ... * 3 * 2 * 1.
This can be simplified as n! (read as "n factorial"), which represents the product of all positive integers from 1 to n.
For example, if we have 4 distinct objects, the number of permutations would be 4! = 4 * 3 * 2 * 1 = 24.
It is important to note that permutations are only applicable when every object is used exactly once and the order matters. If repetitions or restrictions exist, different formulas or approaches may be needed.
Learn more about permutations and factorials
brainly.com/question/23283166
#SPJ11
Anna is making a sculpture in the shape of a triangular prism the triangular bases have sides of length 10m,10m, and 12m and a height of 8m she wants to coat the sculpture in a special finsh that will preserve it longer if the sculpture is 5m thick what is the total area she will have to cover with the finsh?
A. 48m squared
B. 96m squared***
C. 256m squared
D. 480m squared
Just checking my answers pls help
Answers
The total area she will have to cover with the finish is 265 m². Option C
How to determine the areaThe formula for calculating the total surface area of a triangular prism is;
A = bh + ( b₁ + b₂ + b₃ )l
Such that the parameters are;
b is the base of a triangular faceh is the height of a triangular faceb₁ + b₂ + b₃ are the lengths of the basel is the lengthSubstitute the values, we have;
Area = 12(8) + (10 + 10 + 12)5
Multiply the values, we have;
Area = 96 + 32(5)
Area = 96 + 160
add the values
Area = 265 m²
Learn more about area at: https://brainly.com/question/25292087
#SPJ4
A lawn care business is reviewing the number of lawns they mowed during the last 14 weeks. The data is as follows: 41, 36, 20, 28, 30, 24, 24, 31, 22, 34, 25, 27, 27, 25
(a) Create a frequency table using 20 – 24 as the first interval.
(b) Draw a histogram of the frequency table.
(c) Describe the graphs data distribution.
Answers
The frequency table for the above data and the histogram are attached accordingly.
How can the graphs data distribution be described?The graph's data distribution appears to be slightly skewed to the left, with the majority of values concentrated towards the lower end of the range.
The above means tthat the data is more concentrated towards the lower values.
This is suggestive of the fact that there are more occurrences of lower values in the dataset compared to higher values.
Learn more about histogram at:
https://brainly.com/question/16819077
#SPJ1
An ice cream cone is filled exactly level with the top of the cone. The cone has a 7-cm diameter and 9-cm depth. Approximate how much ice cream (in ) is in the cone?
Answers
Approximately, there is 297 cubic centimeters (cc) of ice cream in the cone. The volume of the ice cream cone is (1/3) * (π * 3.5^2) * 9, which simplifies to approximately 297 cc.
The calculation is based on the volume of a cone formula, which states that the volume of a cone is one-third of the product of its base area and height. In this case, the base area is calculated using the diameter of the cone, which is 7 cm, to find the radius (3.5 cm) and then applying the formula for the area of a circle (π * r^2). The height of the cone is given as 9 cm. Thus,
To calculate the volume of the ice cream in the cone, we first need to determine the base area. The formula for the area of a circle is A = π * r^2, where A represents the area and r is the radius. Since the diameter of the cone is 7 cm, the radius is half of that, which equals 3.5 cm. Substituting this value into the area formula, we get A = π * 3.5^2. Next, we use the volume of a cone formula, which is V = (1/3) * A * h, where V represents the volume and h is the height of the cone. Given the height of the cone as 9 cm, we can calculate the volume by substituting the values into the formula as V = (1/3) * (π * 3.5^2) * 9. Simplifying this expression yields a volume of approximately 297 cc, representing the amount of ice cream in the cone.
Learn more about expression here:
https://brainly.com/question/28170201
#SPJ11
It has been found that a worker new to the operation of a certain task on the assembly line will produce P(t) items on day t, where P(t)=24-24e-0.3t,How many items will be produced on the 1st day?what is the maximum number of items, according to the function, the worker can produce?
Answers
Since t cannot be infinity in this case, we conclude that there is no maximum number of items that the worker can produce according to the function.
The number of items produced on the first day can be found by substituting t = 1 into the function P(t):
P(1) = 24 - 24e^(-0.3*1) = 13.24 (rounded to two decimal places)
To find the maximum number of items that the worker can produce, we can take the derivative of the function P(t) with respect to t and set it equal to zero:
P'(t) = 24e^(-0.3t)(0.3) = 7.2e^(-0.3t)
7.2e^(-0.3t) = 0
e^(-0.3t) = 0
t = infinity
However, we can see that as t approaches infinity, P(t) approaches 24. So, we can say that the worker can approach but never exceed 24 items.
Know more about derivative here:
https://brainly.com/question/12944163
#SPJ11
Based on past results found in the Information Please Almanac, there is a 0.1919 probability that a baseball World Series contest will last four games, a 0.2121 probability that it will last five games, a 0.2222 probability that it will last six games, and a 0.3737 probability that it will last seven games. (a) Clearly describe both reasons why this is a valid probability function? (b) Find the mean and standard, variance and deviation (with proper units) for the number of games in World Series contests and interpret the mean. (c) Is it unusual for a team to "sweep" by winning in four games? Why or Why not? ( Use the z-score method)
Answers
(a) This is a valid probability function because the probabilities assigned to each outcome (four games, five games, six games, seven games) are non-negative (greater than or equal to zero) and the sum of all probabilities is equal to 1 (0.1919 + 0.2121 + 0.2222 + 0.3737 = 1).
Why is this a valid probability function?The given probabilities satisfy the fundamental properties of a valid probability function. Each probability value is non-negative, indicating that they are within the valid range of probabilities. Additionally, when we sum up all the probabilities, the total equals 1, which is the requirement for a probability distribution. Therefore, this set of probabilities forms a valid probability function.
(b) To find the mean and standard deviation for the number of games in World Series contests, we need to calculate the expected value and variance based on the given probabilities. The mean, also known as the expected value, is calculated by multiplying each outcome by its respective probability and summing up the results. The variance is computed by subtracting the square of the mean from the expected value of the square of each outcome, weighted by their probabilities. Finally, the standard deviation is the square root of the variance.
(c) Whether it is unusual for a team to "sweep" by winning in four games can be determined by examining the z-score associated with the probability of winning in four games. The z-score measures the number of standard deviations an observation is from the mean. If the z-score falls within a certain range, it is considered usual or unusual based on a predetermined threshold.
To determine if winning in four games is unusual, we would need to calculate the z-score for the probability of winning in four games using the mean and standard deviation derived in part (b). If the z-score is beyond a certain threshold, typically set at ±2 standard deviations, then winning in four games would be considered unusual.
Learn more about probability
brainly.com/question/31828911
#SPJ11
Use the superposition and time-delay properties of (9.5) and (9.6) to determine the z-transform Y(z) in terms of X(z) if y[n]=x[n]−x[n−1] and in the process show that for the first difference system, H(z)=1−z −1
. Linearity of the z-Transform ax 1
[n]+bx 2
[n] ⟷
z
aX 1
(z)+bX 2
(z) Delay of One Sample x[n−1] ⟷
z
z −1
X(z)
Answers
By applying the properties of superposition and time-delay to the given system y[n] = x[n] - x[n-1], we can determine the z-transform Y(z) in terms of X(z) and show that the z-transform of the first difference system, H(z), is equal to 1 - z^(-1).
1. Let's start by applying the superposition property of the z-transform. According to this property, the z-transform of the sum of two sequences is equal to the sum of their individual z-transforms. We can express the given system as y[n] = x[n] + (-1)*x[n-1], where the first term represents x[n] and the second term represents -x[n-1].
2. Using the linearity property of the z-transform, we can find the z-transforms of x[n] and -x[n-1] separately. The z-transform of x[n] is denoted as X(z), and the z-transform of -x[n-1] can be obtained by applying the time-delay property. According to this property, a time delay of one sample corresponds to multiplication by z^(-1) in the z-domain. Therefore, the z-transform of -x[n-1] is z^(-1)X(z).
3. Now, applying the superposition property, the z-transform of y[n] can be written as Y(z) = X(z) + (-1)*z^(-1)X(z). Simplifying this expression, we get Y(z) = (1 - z^(-1))X(z).
4. Comparing this result with the general form of a system's z-transform, Y(z) = H(z)X(z), we can conclude that the z-transform of the first difference system, H(z), is equal to 1 - z^(-1). Hence, we have shown that for the first difference system, H(z) = 1 - z^(-1).
Learn more about z-transform here: brainly.com/question/1542972
#SPJ11
. find all values of p for which the following integral converges: z [infinity] 2 1 x(ln x) p dx.
Answers
The given integral converges when p is less than or equal to -1. For values of p greater than -1, the integral diverges
The integral ∫[1 to 2] x(ln x)^p dx converges for certain values of p.
To determine the values of p for which the given integral converges, we need to analyze its behavior over the interval [1, 2]. The convergence of an integral depends on the integrand's properties and the limits of integration.
In this case, we have the integrand x(ln x)^p. To evaluate its convergence, we consider the behavior of the integrand as x approaches the limits of integration. The term ln x increases as x approaches 0, and when p is positive, raising it to the power of p amplifies this growth. Therefore, the integrand becomes unbounded as x approaches 0.
To ensure convergence, we need to find the values of p for which the integral is bounded. This occurs when the integrand decreases sufficiently fast as x approaches 1. For convergence, p must be less than or equal to -1. When p is less than or equal to -1, the integrand decreases fast enough to offset the growth of ln x, resulting in a convergent integral.
In summary, the given integral converges when p is less than or equal to -1. For values of p greater than -1, the integral diverges. The convergence or divergence of the integral is determined by the interplay between the growth of ln x and the exponent p.
Learn more about convergence here:
https://brainly.com/question/29258536
#SPJ11
determine whether the relation r on the set of all people is reflexive, symmetric, antisymmetric, and/or transitive, where (a, b) ∈ r if and only if____(check all that apply.) if
(a) a is taller than b.
(b) a and b are born on the same day.
(c) a has the same first name as b.
(d) a and b have a common grandparent.
Answers
By analyzing the properties of the relation in each definition, we can gain insights into the nature of the relationships between individuals in the set, and how they are related to each other through different criteria. Here the statments a)is transitive b)is transitive ,antisymmetric and symmetric c) symmetric ,anti symmetric and transitive d)reflexive and transitive
(a) a is taller than b.
Reflexive: The relation is not reflexive, since a person cannot be taller than themselves.
Symmetric: The relation is not symmetric, since if a is taller than b, it does not imply that b is taller than a.
Antisymmetric: The relation is not antisymmetric, since there can be cases where a is taller than b, and b is taller than a (for example, if they are the same height).
Transitive: The relation is transitive, since if a is taller than b and b is taller than c, then it follows that a is taller than c.
(b) a and b are born on the same day.
Reflexive: The relation is not reflexive, since a person cannot be born on the same day as themselves.
Symmetric: The relation is symmetric, since if a is born on the same day as b, then b is born on the same day as a.
Antisymmetric: The relation is antisymmetric, since if a is born on the same day as b and b is born on the same day as a, then it follows that a and b are the same person.
Transitive: The relation is transitive, since if a is born on the same day as b and b is born on the same day as c, then it follows that a is born on the same day as c.
(c) a has the same first name as b.
Reflexive: The relation is not reflexive, since a person does not have the same first name as themselves (unless they have a very unique name, but this is not the usual case).
Symmetric: The relation is symmetric, since if a has the same first name as b, then b has the same first name as a.
Antisymmetric: The relation is antisymmetric, since if a has the same first name as b and b has the same first name as a, then it follows that a and b are the same person.
Transitive: The relation is transitive, since if a has the same first name as b and b has the same first name as c, then it follows that a has the same first name as c.
(d) a and b have a common grandparent.
Reflexive: The relation is reflexive, since a person has themselves as a grandparent.
Symmetric: The relation is not symmetric, since if a has b as a grandparent, it does not imply that b has a as a grandparent (for example, b could be a grandparent of a, but a could be younger than b and not yet have any grandchildren).
Antisymmetric: The relation is not antisymmetric, since there can be cases where a has b as a grandparent and b has a as a grandparent, without a and b being the same person (for example, if a and b are siblings who married siblings, then their children would have the same grandparents on both sides).
Transitive: The relation is transitive, since if a has b as a grandparent and b has c as a grandparent, then it follows that a has c as a grandparent (since they must share a common ancestor).
Learn more about relation : https://brainly.com/question/29561989
#SPJ11
Suppose income taxes fall by $20 billion. As a result of the increased deficit, interest rates rise, and this reduces investment expenditures by $15 billion. The MPC is 0.9. Crowding out is a. less than zero. b. zero. c. incomplete. d. complete.
Answers
Crowding out refers to the phenomenon where increased government spending or borrowing reduces private sector spending or investment.
In this scenario, income taxes fall by $20 billion, leading to an increased deficit. As a result of the increased deficit, interest rates rise, which reduces investment expenditures by $15 billion.
To determine the extent of crowding out, we need to consider the relationship between changes in government spending and changes in private sector spending. The marginal propensity to consume (MPC) measures the fraction of additional income that is spent.
In this case, the MPC is given as 0.9, which means that for every additional dollar of income, individuals spend 90 cents and save 10 cents. With a high MPC, a decrease in income taxes (increase in disposable income) is expected to result in a significant increase in consumer spending.
However, the increase in the deficit and subsequent rise in interest rates can have a dampening effect on private sector investment. The higher interest rates make borrowing more expensive, reducing the incentive for businesses to invest.
Based on the given information, it can be inferred that the crowding out effect is incomplete (option c). While the decrease in income taxes stimulates consumer spending, the subsequent increase in interest rates partially offsets this effect by reducing investment expenditures. The overall impact on private sector spending is not fully negated (complete crowding out) nor completely unaffected (zero crowding out).
Learn more about Crowding here: brainly.com/question/32386564
#SPJ11
Kiran is playing a video game. He earns 3 stars for each easy level he completes and 5 stars for each difficult level he completes. He completes more than 20 levels total and earns 80 or more stars.
Let `x` represent the number of easy levels that Kiran completes.
Let `y` represent the number of difficult levels that Kiran completes
Answers
Based on the given information, we can set up inequalities to determine the possible combinations of levels that Kiran could have completed to earn 80 or more stars, with the total number of levels being greater than 20.
Let's analyze the given information. Kiran earns 3 stars for each easy level completed and 5 stars for each difficult level completed. The total number of levels completed can be represented as `x + y`. The total number of stars earned can be calculated as 3x + 5y. According to the given conditions, the total number of levels completed is greater than 20, so we have the inequality x + y > 20. Additionally, the total number of stars earned is 80 or more, leading to the inequality 3x + 5y ≥ 80.
By setting up these inequalities, we can explore different combinations of `x` and `y` that satisfy the conditions. For example, if Kiran completes 10 easy levels (x = 10), he would need to complete at least 11 difficult levels (y ≥ 11) to meet the requirements. Similarly, other combinations can be explored to find valid solutions. The goal is to find the combinations of `x` and `y` that satisfy both inequalities and result in a total number of stars earned equal to or greater than 80.
Learn more about inequalities here:
https://brainly.com/question/30238773
#SPJ11
use taylor's formula to construct a quadratic approximation to \displaystyle f(x,y)=xe^{y} e^xf(x,y)=xe y e x near the origin
Answers
A quadratic approximation to \displaystyle f(x,y)=xe^{y} e^xf(x,y)=xe y e x near the origin is \displaystyle Q(x,y)=xy+xy^{2} Q(x,y)=xy+xy^2.
How can we approximate \displaystyle f(x,y)=xe^{y} e^xf(x,y)=xe y e x near the origin using a quadratic function?A quadratic approximation to a function \displaystyle f(x,y) f(x,y) can be constructed using Taylor's formula. In this case, we are looking to approximate the function \displaystyle f(x,y)=xe^{y} e^xf(x,y)=xe y e x near the origin. Taylor's formula allows us to express a function as a sum of its partial derivatives evaluated at a specific point, multiplied by the corresponding power of the variables.
To find the quadratic approximation, we start by calculating the first-order partial derivatives of \displaystyle f(x,y) f(x,y) with respect to \displaystyle x x and \displaystyle y y, which are \displaystyle f_{x}=e^{y}+ye^{y} x+e y +y e and \displaystyle f_{y}=xe^{y} x e y , respectively. Evaluating these derivatives at the origin \displaystyle (0,0) (0,0), we get \displaystyle f_{x}(0,0)=1 f_x(0,0)=1 and \displaystyle f_{y}(0,0)=0 f_y(0,0)=0.
Using the Taylor expansion, the quadratic approximation \displaystyle Q(x,y) Q(x,y) can be written as:
\displaystyle Q(x,y)=f(0,0)+f_{x}(0,0)x+f_{y}(0,0)y+\frac{1}{2}\left[f_{xx}(0,0)x^{2}+2f_{xy}(0,0)xy+f_{yy}(0,0)y^{2}\right]
Since the second-order partial derivatives \displaystyle f_{xx},f_{xy},f_{yy} f_xx, f_xy, f_yy are not given, we consider only the terms up to the quadratic order. Plugging in the values we obtained, the quadratic approximation to \displaystyle f(x,y)=xe^{y} e^xf(x,y)=xe y e x near the origin becomes:
\displaystyle Q(x,y)=xy+xy^{2}
This approximation provides a reasonable estimate of the function \displaystyle f(x,y) f(x,y) in the neighborhood of the origin, capturing the linear and quadratic behavior of the function. However, it should be noted that as we move away from the origin, the accuracy of the quadratic approximation decreases.
Learn more about Taylor's formula
brainly.com/question/31396637
#SPJ11
4 points item at position 13 given sorted list: { 4 11 17 18 25 45 63 77 89 114 }. how many list elements will be checked to find the value 77 using binary search?
Answers
Binary search works by dividing the sorted list in half repeatedly until the target value is found or it is determined that the value is not present in the list. In the worst case, the value is not present in the list and the search must continue until the remaining sub-list is empty.
The binary search checked a total of 3 elements to find the value 77.
In this case, the list has 10 elements and we are searching for the value 77.
Start by dividing the list in half:
{ 4 11 17 18 25 } | { 45 63 77 89 114 }
The target value 77 is in the right sub-list, so we repeat the process on that sub-list:
{ 45 63 } | { 77 89 114 }
The target value 77 is in the left sub-list, so we repeat the process on that sub-list:
{ 77 } | { 89 114 }
We have found the target value 77 in the list.
Therefore, the binary search checked a total of 3 elements to find the value 77.
To know more about binary search refer here:
https://brainly.com/question/12946457
#SPJ11
Suggest how similar electron arrangements result in similar
chemical properties. Refer to elements in the noble gas
family in your explanation
Answers
Elements having similar electron arrangements exhibit comparable chemical properties. The chemical properties of elements depend mainly on the valence electrons. The valence electrons are the electrons in the outermost shell of the atom, which take part in chemical reactions.
The elements in the noble gas family have completely filled s and p subshells, except for helium, which has just two electrons in its valence shell.
Therefore, the elements in the noble gas family have similar electron arrangements. This means that they all have the same number of electrons in the outermost shell. Hence, they have similar chemical properties. Since the outer shell is fully occupied in the noble gases, they are very stable and have low reactivity.Therefore, they do not readily react with other elements to form compounds.
This is because it takes a lot of energy to remove an electron from their outermost shell, or to add an electron to it. Hence, they are chemically inert and very unreactive.The noble gases are important for their lack of chemical reactivity. They are used in various applications where their unreactivity is needed, such as in light bulbs and welding torches. Helium is used to fill balloons, blimps, and airships due to its low density and non-reactivity with other elements.The similarity of the noble gases in terms of their electron arrangements suggests that other elements in other families with similar electron arrangements will also have similar chemical properties.
To know more about electron arrangements visit:
https://brainly.com/question/31972462
#SPJ11
find the area of the region under the graph of the function f on the interval [−1, 4]. f(x) = 2x 5
Answers
Answer:
Step-by-step explanation:
To find the area of the region under the graph of the function f(x) = 2x + 5 on the interval [-1, 4], we need to integrate the function over that interval.
The integral of f(x) with respect to x over the interval [-1, 4] gives us the area under the curve.
∫[a,b] f(x) dx denotes the integral of f(x) with respect to x over the interval [a,b].
In this case, we have:
∫[-1,4] (2x + 5) dx
Evaluating this integral, we get:
∫[-1,4] (2x + 5) dx = [x^2 + 5x] evaluated from -1 to 4
Plugging in the upper and lower limits, we have:
= (4^2 + 5(4)) - ((-1)^2 + 5(-1))
= (16 + 20) - (1 - 5)
= 36 + 4
= 40
Therefore, the area of the region under the graph of the function f(x) = 2x + 5 on the interval [-1, 4] is 40 square units.
If a 6. 2% Social Security tax is applied to a maximum wage of $106,800, the maximum amount of Social Security tax that could ever be charged in a single year is: a. $213. 60 b. $6,408. 00 c. $6,621. 60 d. $17,225. 81 Please select the best answer from the choices provided A B C D.
Answers
The correct answer is C.$106,800 is the maximum wage that is subject to the 6.2 percent Social Security tax.
If a 6.2% Social Security tax is applied to a maximum wage of $106,800,
the maximum amount of Social Security tax that could ever be charged in a single year is $6,621.60.
The correct answer is C.$106,800 is the maximum wage that is subject to the 6.2 percent Social Security tax.
Therefore, the maximum amount of Social Security tax that can be charged to an individual in a single year is $6,621.60, which is calculated as follows:
$106,800 × 6.2% = $6,621.60.
This is the maximum amount of Social Security tax that can be charged to an individual in a single year.
To know more about Security tax visit:
https://brainly.com/question/1473508
#SPJ11
Identify the base in the expression 8 X 8 X 8
Answers
Answer:
Step-by-step explanation:
8^3
Given the function f(x)=4x−8, find the net signed area between f(x) and the x-axis over the interval [−5,6].
Answers
We know that the net signed area between f(x)=4x−8 and the x-axis over the interval [−5,6] is 46.
Given the function f(x)=4x−8, we need to find the net signed area between f(x) and the x-axis over the interval [−5,6].
To do this, we need to first plot the graph of the function f(x)=4x−8.
The graph of the function is a straight line passing through the y-axis at −8 and with a slope of 4.
Next, we need to find the x-intercepts of the function. To do this, we set f(x)=0 and solve for x.
0=4x−8
4x=8
x=2
So the x-intercept of the function is (2,0).
Now we can find the net signed area between f(x) and the x-axis over the interval [−5,6].
The interval [−5,6] includes the x-intercept at x=2.
The area below the x-axis from x=−5 to x=2 is given by the integral ∫−5^2 f(x)dx.
∫−5^2 (4x−8)dx = [2x^2−8x]−5^2 = [(2×2^2−8×2)−(2×(−5)^2−8×(−5))]
= [−4−(−90)] = 86
The area above the x-axis from x=2 to x=6 is given by the integral ∫2^6 f(x)dx.
∫2^6 (4x−8)dx = [2x^2−8x]2^6 = [(2×6^2−8×6)−(2×2^2−8×2))]
= [44−4] = 40
Therefore, the net signed area between f(x) and the x-axis over the interval [−5,6] is 86−40=46.
So the answer is: The net signed area between f(x)=4x−8 and the x-axis over the interval [−5,6] is 46.
To know more about x-axis refer here
https://brainly.com/question/2491015#
#SPJ11
where σ2 is known and n = 50. from your data, you calculate your test statistic value as 2.01.
Answers
Based on the information provided, it seems like you have conducted a hypothesis test where the population variance (σ2) is known and the sample size (n) is 50.
To interpret this result, you would need to compare the test statistic value to a critical value from a statistical table or calculator. This critical value represents the threshold for rejecting the null hypothesis, which is typically set at a significance level of 0.05.
If the test statistic value is greater than the critical value, then you can reject the null hypothesis and conclude that there is evidence to support the alternative hypothesis. On the other hand, if the test statistic value is less than the critical value, then you fail to reject the null hypothesis and cannot conclude that there is evidence to support the alternative hypothesis.
Without knowing the specific hypotheses being tested or the critical value for your test, it is difficult to provide a more detailed answer.
To know more about hypothesis visit:
https://brainly.com/question/29519577
#SPJ11
A sample of n = 22 is taken and the sample mean is =35 and a sample standard deviation of s= 9.38. Construct a 95% confidence interval for the true mean, µ.
(33, 37)
(31.56, 38.44)
(30.84, 39.16)
(25.62, 44.38)
Answers
The answer is (B) (31.56, 38.44) which means we are 95% confident that the true population mean lies between 31.56 and 38.44.
The 95% confidence interval for the population mean, µ, is given by:
CI = ± tα/2 * (s/√n)
where is the sample mean, s is the sample standard deviation, n is the sample size, and tα/2 is the t-value with (n-1) degrees of freedom at the α/2 level of significance.
Here, = 35, s = 9.38, and n = 22. From the t-distribution table with (n-1) = 21 degrees of freedom and a 95% confidence level, we have tα/2 = 2.08.
Plugging in the values, we get:
CI = 35 ± 2.08 * (9.38/√22)
= (31.56, 38.44)
Know more about 95% confidence interval here:
https://brainly.com/question/15683202
#SPJ11
80 points
Factor 360 t + 10 t3 - 120 t2 .
10t(t - 6) 2
-10t(t - 6)(t + 6)
10t(t - 6)(t + 6)
Answers
Answer:
The factorization of 360t + 10t^3 - 120t^2 is 10t(t - 6)(t + 6).
Step-by-step explanation:
The factorization of 360t + 10t^3 - 120t^2 is 10t(t - 6)(t + 6).
To factor the expression 360t + 10t^3 - 120t^2, we can begin by factoring out the greatest common factor, which is 10t:
10t(36 + t^2 - 12t)
We can then factor the trinomial inside the parentheses using the quadratic formula, or by completing the square. However, we notice that the trinomial can be rewritten as (t - 6)^2 - 36:
10t((t - 6)^2 - 36)
We can then apply the difference of squares formula to further factor the expression:
10t(t - 6 + 6)(t - 6 - 6)
Simplifying, we get:
10t(t - 6)(t + 6)
Therefore, the fully factored form of the expression 360t + 10t^3 - 120t^2 is 10t(t - 6)(t + 6).
use the ratio test to determine whether the series is convergent or divergent. [infinity]n=0 (−9)n (2n + 1)! n = 0
Answers
As n approaches infinity, this ratio approaches 1. Therefore, the series diverges by the ratio test.
The ratio test states that if the limit of the absolute value of the ratio of the (n+1)th term to the nth term is less than 1, then the series converges. Using this test, we can see that the absolute value of the ratio of the (n+1)th term to the nth term is:
|((-9)ⁿ⁺¹ * (2(n+1) + 1)!)/((-9)ⁿ * (2n + 1)!)|
Simplifying this expression, we get:
|(-9) * (2n + 3) * (2n + 2)/(2n + 1)(2n + 2)(-9)|
Which simplifies further to:
|2n + 3|/(2n + 1)
In summary, we used the ratio test to determine the convergence/divergence of the given series. The test involves taking the absolute value of the ratio of the (n+1)th term to the nth term and finding the limit as n approaches infinity.
If the limit is less than 1, the series converges; if the limit is greater than 1, the series diverges; and if the limit is equal to 1, the test is inconclusive and another test must be used. In this case, the limit was equal to 1, so we concluded that the series diverges.
To know more about ratio test click on below link:
https://brainly.com/question/15586862#
#SPJ11
ONLY ANSWER IF YOU KNOW. What is the probability that either event will occur?
Answers
Answer:
Step-by-step explanation: